
NLP an introduction
A Gentle Introduction to Natural Language Processing
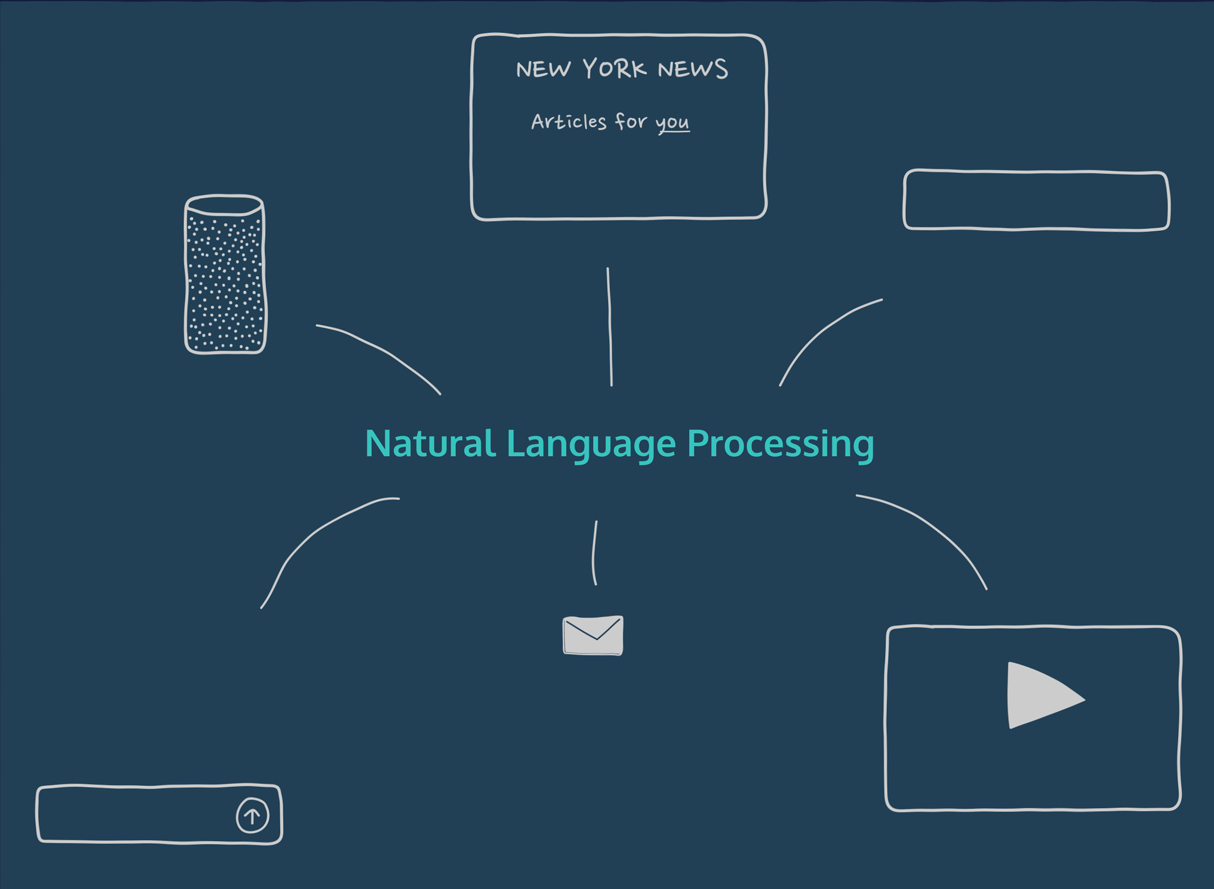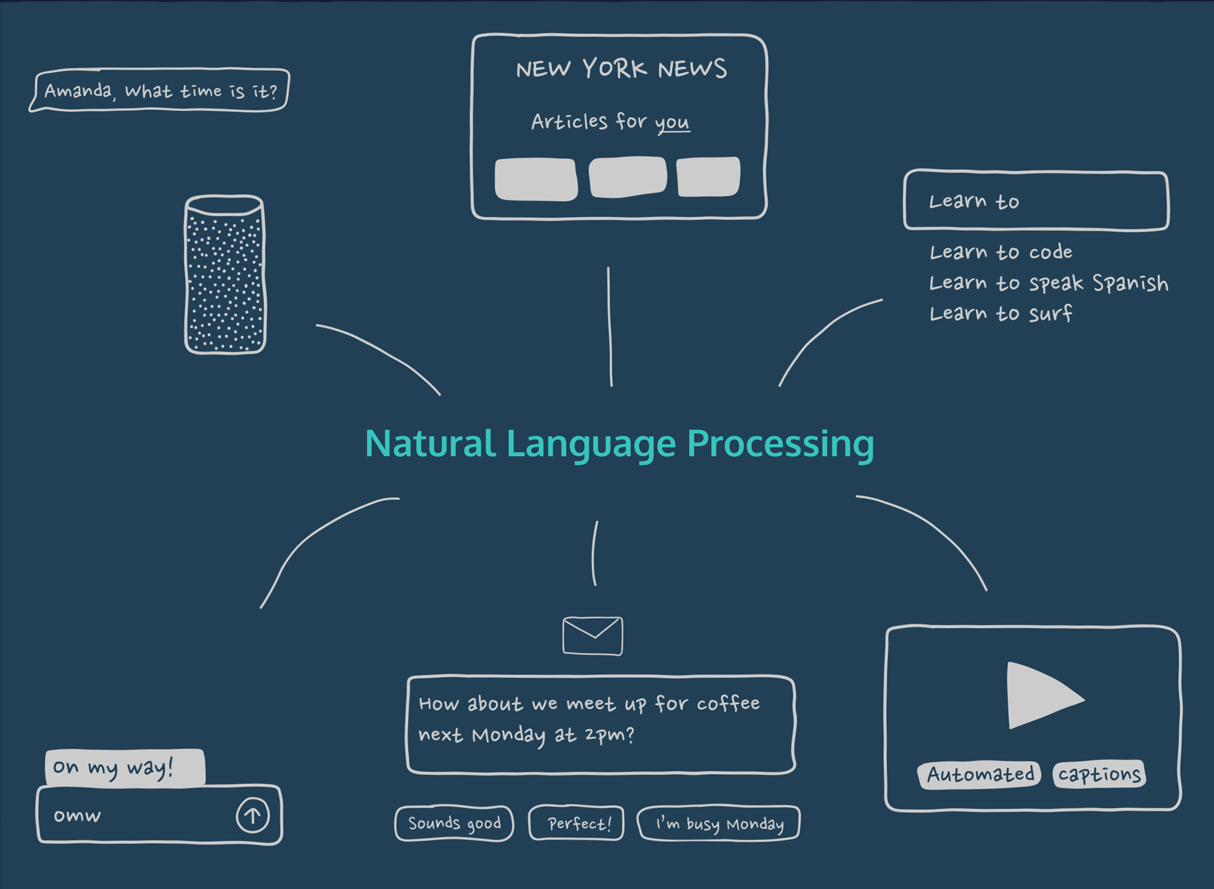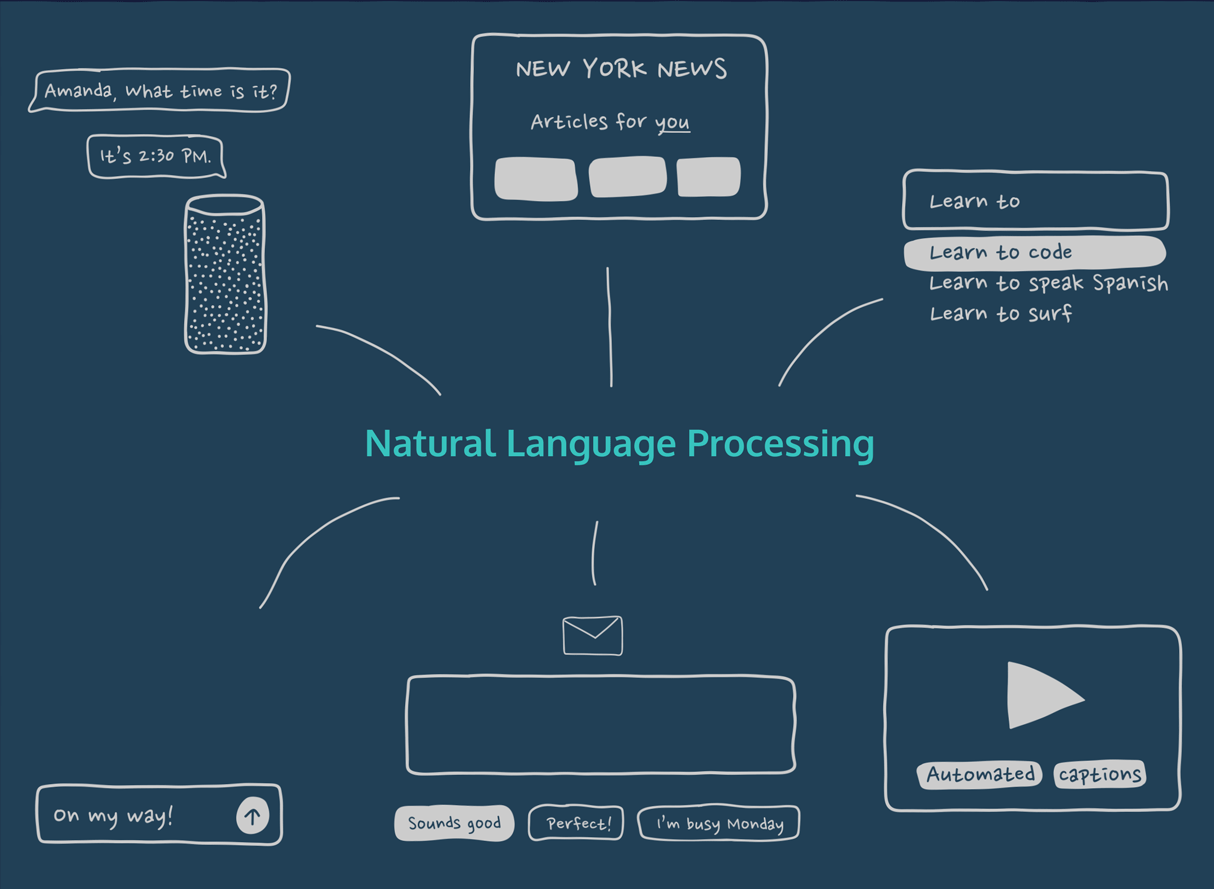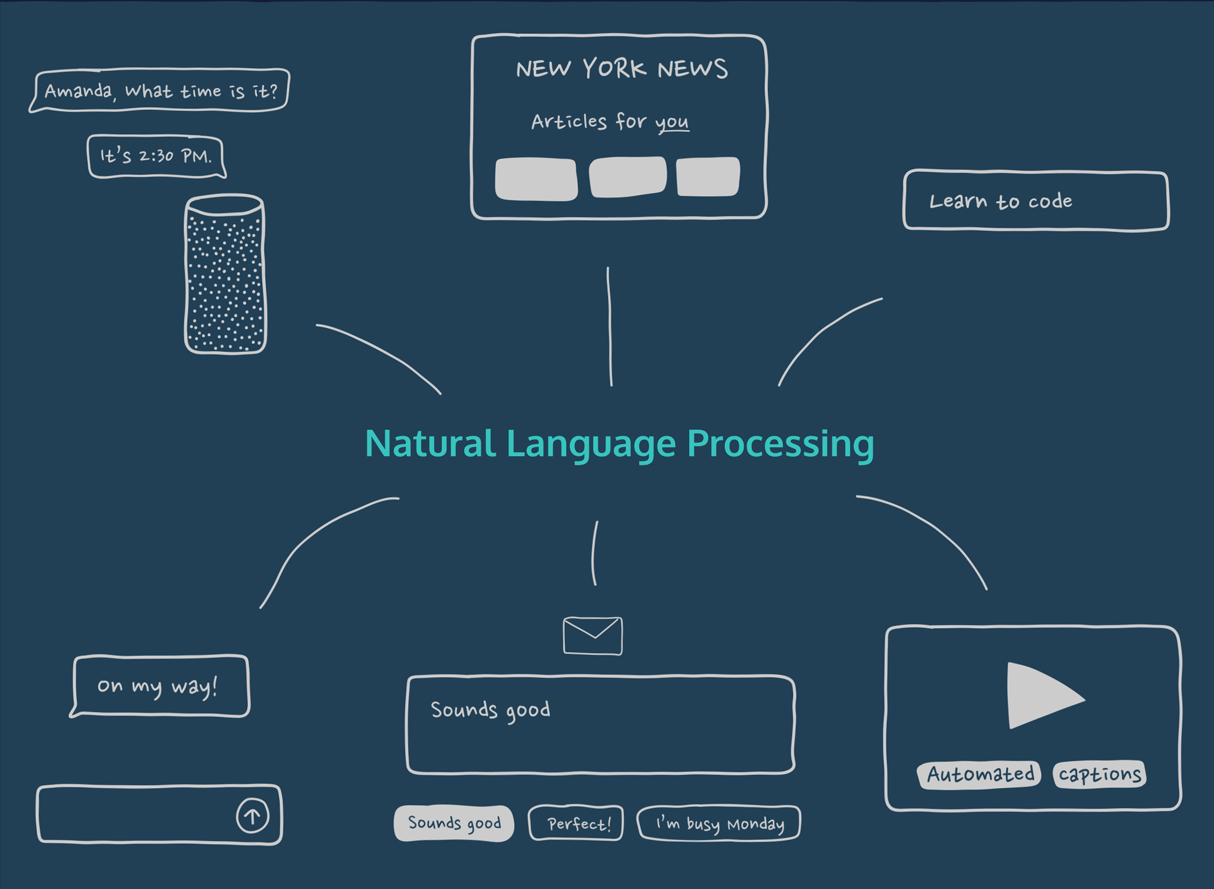
Humans communicate through some form of language either by text or speech. Now to make interactions between computers and humans, computers need to understand natural languages used by humans. Natural language processing is all about making computers learn, process, and manipulate natural languages.
In this blog, we will look at some of the common practices used in Natural language processing tasks. And build a simple Sentiment Analysis Model on movie reviews to predict whether the given review is positive or negative.
What is Natural Language Processing(NLP)?
NLP is a branch of artificial intelligence that deals with analyzing, understanding, and generating the languages that humans use naturally in order to interface with computers in both written and spoken contexts using natural human languages instead of computer languages.
Applications of NLP
- Machine translation(Google Translate)
- Natural language generation
- Web Search
- Spam filters
- Sentiment Analysis
- Chatbots
… and many more
Data Cleaning:
In the data cleaning process, we remove special characters, symbols, punctuation, HTML tags<>, etc from the raw data which contains no information for the model to learn, these simply noise in our data.
This process also depends on the problem statement, like what to remove from raw text. For example, if the problem contains text from the economics or business world then symbols like $ or other currency symbols may contain some hidden information that we do not want to lose. But in most cases we remove them.
Preprocessing of data:
Preprocessing of data is a data mining technique that involves transforming the raw data into an understandable format.
Lowercase:
Making all the text lower case is one of the simplest and most effective forms of text preprocessing.

Tokenization:
Tokenization is the process of breaking up text document into individual words called tokens.
As seen above sentence is broken down into words(tokens). Natural language toolkit(NLTK) is a popular open source library used extensively for NLP tasks. For this blog, we will use nltk for all the text preprocessing steps.
You can download nltk library using pip:
!pip install nltk
Stop words removal:
Stop words are common words that do not contribute much of the information in a text document. Words like ‘the’, ‘is’, ‘a’ have less value and add noise to the text data.
There is an in-built stopword list in NLTK which we can use to remove stop words from text documents. However this is not the standard stopwords list for every problem, we can also define our own set of stopwords based on the domain.
NLTK has a predefined list of stop words. We can add or remove stopwords from this list or use them as it is based on the specific task.
Stemming:
Stemming is the process of reducing a word to its stem/root word. It reduces inflection in words (e.g. ‘help’, ’helping’, ’helped’, ’helpful’) to their root form (e.g. ‘help’). It removes the morphological affixes from words, leaving only the word stem.

The stem word may or may not be a valid word in the language. For example ‘movi’ is the root word for ‘movie’, and ‘emot’ is the root word for ‘emotion’.
Lemmatization:
Lemmatization does the same thing as stemming, converting a word to its root form but with one difference i.e., the root word, in this case, belongs to a valid word in the language. For example, the word caring would map to ‘care’ and not ‘car’ in case of stemming.
WordNet is a database of valid words in the English language. NLTK’s WordNetLemmatizer() uses valid words from WordNet.
N-grams:

N-grams are the combination of multiple words used together, Ngrams with N=1 is called unigrams. Similarly, bigrams (N=2), trigrams (N=3), and so on can also be used.
N-grams can be used when we want to preserve sequence information in the document, like what word is likely to follow the given one. Unigrams don’t contain any sequence information because each word is taken individually.
Text Data Vectorization:
The process of converting text into numbers is called text data vectorization. Now after text preprocessing, we need to numerically represent text data i.e., encoding the data in numbers which can be further used by algorithms.
Bag of words(BOW):
It is one of the simplest text vectorization techniques. The intuition behind BOW is that two sentences are said to be similar if they contain a similar set of words.
Consider these two sentences:

In NLP tasks, each text sentence is called a document and collection of such documents is referred to as text corpus.
BOW constructs a dictionary of d unique words in the corpus(collection of all the tokens in data). For example corpus in the above image is made up of combined words in S1 and S2.
Now, we can think of like creating a table where columns are all the set of unique words in the corpus with each row corresponding to a sentence(document). We set the value as 1 if the word is present in the sentence else we set it to 0.

This will create a matrix of dxn where d is the total number of unique tokens in the corpus and n equals the number of documents. In the above example, the matrix will be of shape 11x2.
TF-IDF:

It stands for Term Frequency(TF)-Inverse Document Frequency.
Term Frequency:
Term Frequency defines the probability of finding a word in the document. Now let’s say we want to find what is the probability of finding a word wi in document dj.
Term Frequency(wi, dj) =
Number of times wi occurs in dj/Total number of words in dj
Inverse Document Frequency:
The intuition behind IDF is that a word is not of much use if it is appearing in all the documents. It defines how unique is the word in the total corpus.
IDF(wi, Dc) = log(N/ni)
Here, Dc = All documents in the corpus,
N = Total number of documents,
ni = documents which contain word (wi).
If wi is more frequent in the corpus then IDF value decreases.
If wi is not frequent which means ni decreases and hence IDF value increases.
TF(wi, dj) * IDF(wi, Dc)
TF-IDF is the multiplication of TF and IDF values. It gives more weightage to words that occurs more in the document and less in the corpus.
Sentiment Analysis: IMDB Movie Reviews
About
The dataset contains a collection of 50,000 reviews from the IMDB Website with an equal number of positive and negative reviews. The task is to predict the polarity (positive or negative) of a given review(text).
I used Deepnote to do the data analysis on IMDB dataset, its easy and fast to setup plus provides great collaboration tools. What I most like is the ability to plug and play from multiple data sources. If you are new and starting your data science journey I highly recommend to check it out. Here is the notebook for this project.
1. Loading and exploration of Data
IMDB Dataset can be downloaded from here.
Dataset overview:
Positive reviews are labeled as 1 and negative as 0.
Sample positive review:
Sample negative review:
2. Data preprocessing
Here we are doing all the steps of data cleaning and preprocessing in one method as discussed above. We are using lemmatization and not stemming because while testing results with both, lemmatization gives slightly better results compared to stemming.
Usage of stemming or lemmatization or both depends on the problem, so we should try and see which way works best for the given task.
Adding a new column preprocessed_review in the dataframe by applying data_preprocessing() on all the reviews.
3. Vectorizing Text(reviews)
Splitting the data set into train and test(70–30):
We are using sklearn’s train_test_split to split data into train and test. Here we are using parameter stratify, to have an equal proportion of classes in train and test.
BOW
Here we have used min_df=10 as we only want those words which occur at least 10 times in the whole corpus.
TF-IDF
4. Building ML Classifiers
Naive Bayes with reviews BOW encoded
Naive Bayes with BOW gives an accuracy of 84.6%. Let’s try with TF-IDF.
Naive Bayes with reviews TF-IDF encoded
TF-IDF gives slightly better results(85.3%) than BOW. Now let’s try TF-IDF with a simple linear model, Logistic Regression.
Logistic Regression with reviews TF-IDF encoded
Logistic Regression with reviews TFIDF encoded gives better results than Naive Bayes with an accuracy of 88.0%.
Plotting the confusion matrix gives us information about how many of the data points are correctly and incorrectly classified by the model.
Out of 7500 negative reviews, 6515 were correctly classified as negative and 985 were incorrectly classified as positive. Out of 7500 positive reviews, 6696 were correctly classified as positive and 804 were incorrectly classified as negative.
Summary
We have learned some basic NLP tasks and built simple ML Models for sentiment analysis of movie reviews. Further improvements can be achieved by trying word embedding with deep learning models.